在 node.js 中,可以使用 net 模块建立基于 Unix domain socket 或 Windows named pipe 的通信渠道,以便同本机系统内的其他进程彼此通信,互相收发消息或指令,实现进程间通信(IPC,Inter Process Communication)。例如:
// server.ts
import net from 'net';
import v8 from 'v8';
let client: net.Socket | null = null;
const server = net.createServer((c: net.Socket) => {
if (client) {
return;
}
console.log('client connected');
c.on('end', () => {
console.log('client disconnected');
client = null
});
c.on('data', (buffer: Buffer) => {
console.log('receive data:', buffer);
receive(buffer);
});
client = c;
});
server.on('error', (err) => {
throw err;
});
server.listen('/tmp/example.sock', () => {
console.log('server bound');
});
function send(message: any) {
client!.write(v8.serialize(message));
}
function receive(buffer: any) {
// TODO: parse and response
}
// client.ts
import net from 'net';
import v8 from 'v8';
const client = new net.Socket();
client.on('data', (buffer: Buffer) => {
console.log('receive data:', buffer);
receive(buffer);
});
client.on('error', (err) => {
throw err;
});
client.on('connect', () => {
console.log('connected');
});
client.on('close', () => {
console.log('connection closed');
});
function send(message: any) {
client.write(v8.serialize(message));
}
function receive(buffer: any) {
// TODO: parse and response
}
以上代码实现了两个 node.js 进程通过 unix socket 进行彼此通信。通信的双方(Server & Client)使用 v8.serialize 将需要发送的数据序列化为 buffer,并写入 socket,发给对方;对方再通过 net.Socket 提供的 data 事件接收到该数据,并进行解析、响应。
然而,net.Socket 本质上是一个全双工的读写流,通过 data 事件获取到的 buffer 并没有固有的消息边界:它可能是某个消息的某一部分,也可能是多个消息的组合:
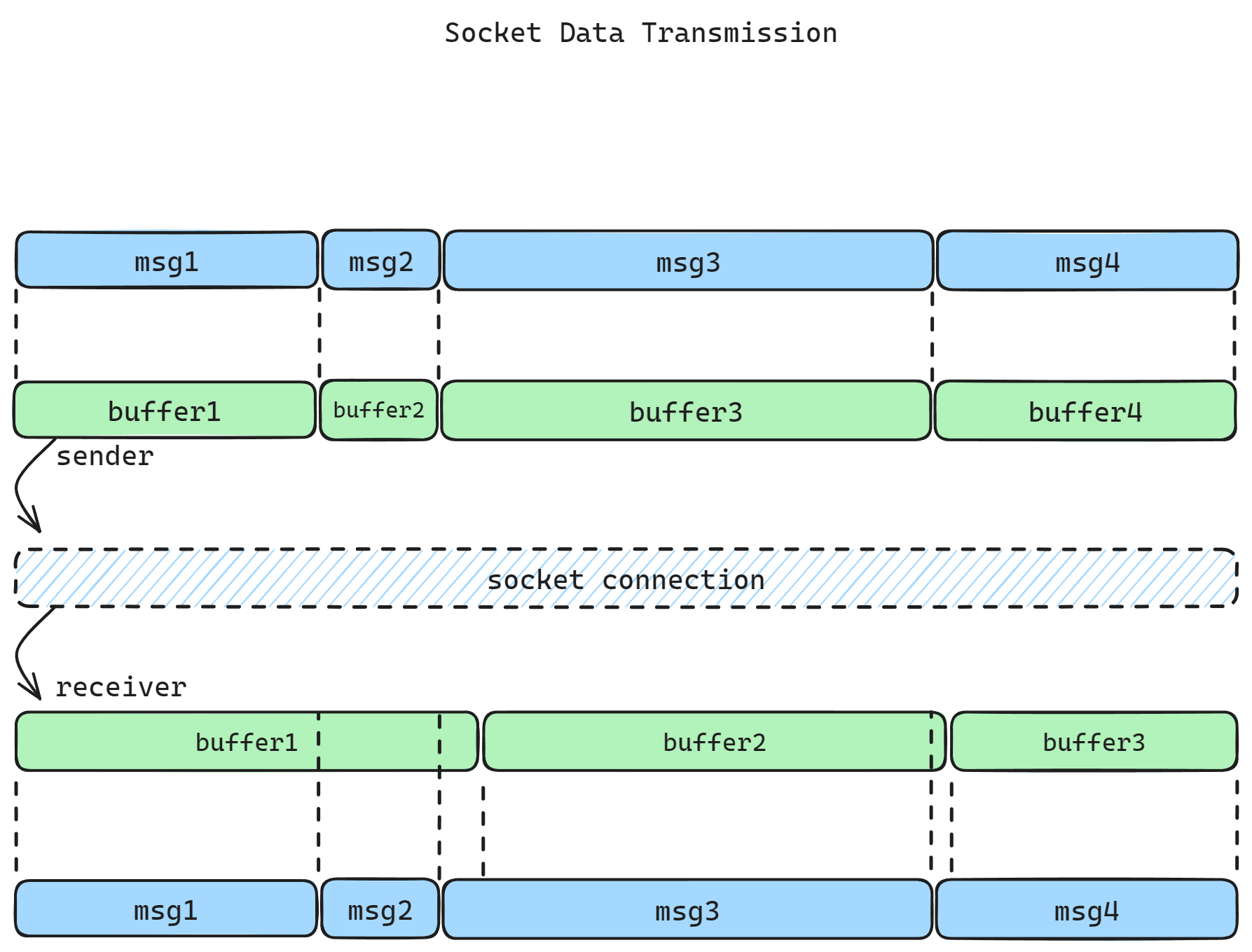
如何解析收到的 buffer 并找到找到正确的消息边界,可能是一个棘手的问题。以下我们介绍三种处理消息边界的常用方法,并提供样例代码以供参考。
固定长度法
一种最简单的处理方法为固定长度法。发送者和接受者就传输消息的长度达成约定,例如,规定发送者每次发送消息的长度一定是 1024 个 uint8,不足的填充空字符;接收者在收消息时,每收到 1024 个 uint8,则进行一次消息解析,读出真正携带的信息。
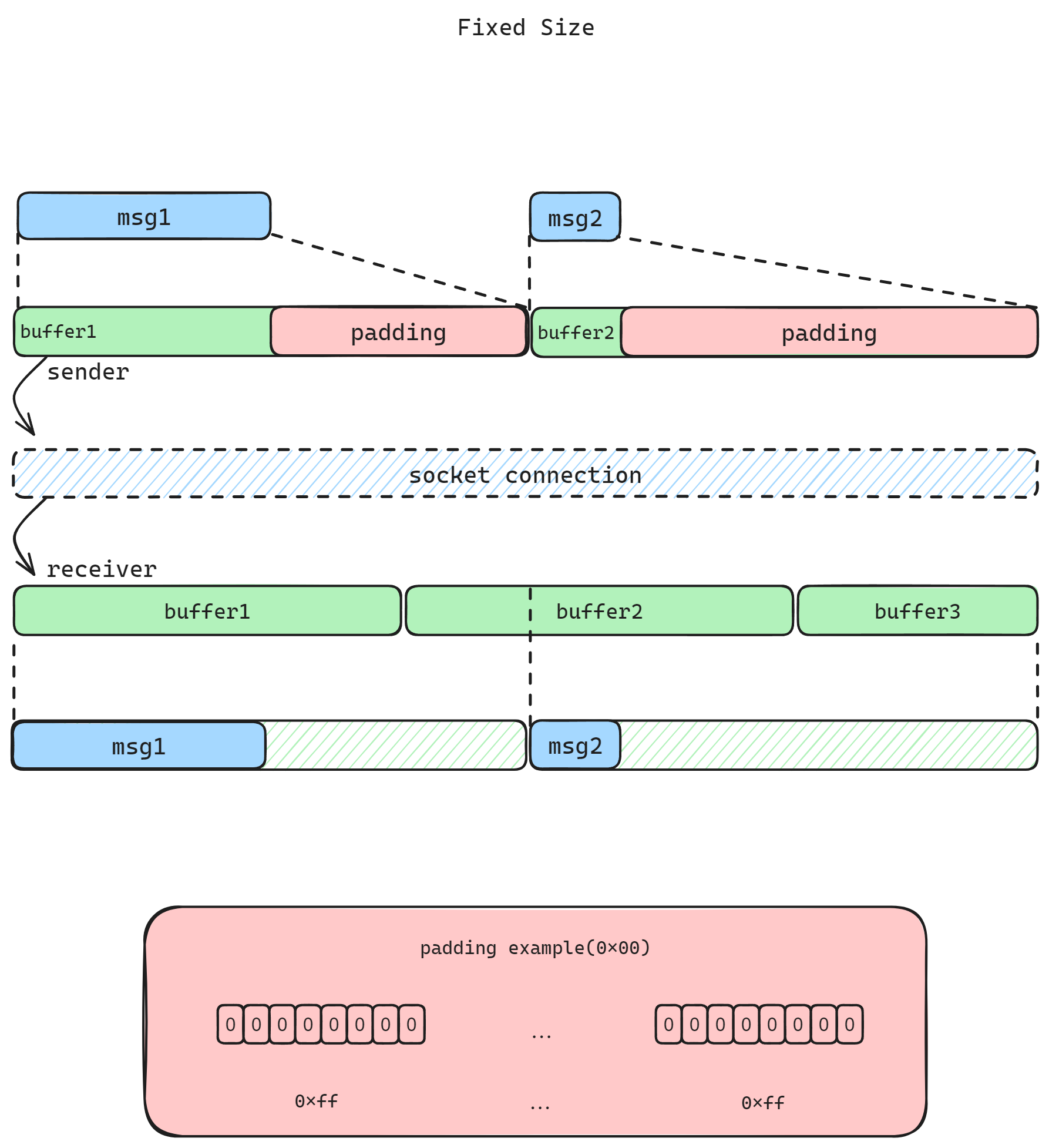
代码样例:
// 约定的消息长度
const MSG_PACKET_SIZE = 1024;
function send(message: any) {
const msgBuffer = v8.serialize(message);
// 超长,则抛出错误
if (msgBuffer.length >= MSG_PACKET_SIZE) {
throw new Error(`cannot send message larger than ${MSG_PACKET_SIZE} bytes`);
}
// 不足,则补足长度
const fillLength = MSG_PACKET_SIZE - msgBuffer.length;
const fillBuffer = Buffer.alloc(fillLength);
const data = Buffer.concat([msgBuffer, fillBuffer]);
client!.write(data);
}
// 待处理的字节
let pendingBuffer: Buffer = Buffer.alloc(0);
function receive(data: Buffer) {
pendingBuffer = Buffer.concat([pendingBuffer, data]);
function parse(packetBuffer: Buffer) {
let fillIndex = 0;
// 找出补位序号
for (let i = packetBuffer.length - 1; i >= 0; i--) {
if (packetBuffer[i] === 0) {
fillIndex = 0;
} else {
break;
}
}
const msgBuffer = packetBuffer.slice(0, fillIndex);
// 反序列化,得到真正的消息内容
console.log('receive msg:', v8.deserialize(msgBuffer));
}
// 解析每一块数据
do {
const packetBuffer = pendingBuffer.slice(0, MSG_PACKET_SIZE);
pendingBuffer = pendingBuffer.slice(MSG_PACKET_SIZE);
parse(packetBuffer);
} while (pendingBuffer.length >= MSG_PACKET_SIZE);
}
显而易见,这种方法理解和处理上都比较较简单,但是对消息长度有严苛的限制,超过约定的固定长度则无法传输(或需要采用分片发送、截取等策略),并且无论消息实际内容多少,最终都需要补全到固定长度,在发送较少信息时,会产生较多的额外的字节传输。
分隔符法
另一种常用的方式为分隔符法。发送者在消息内容末尾增加某个特定的分隔符(字符或字符序列),用来标记消息已结束。接受者在收到消息时,只要找到该分隔符,便提取之前的字节流作为完整的消息内容。
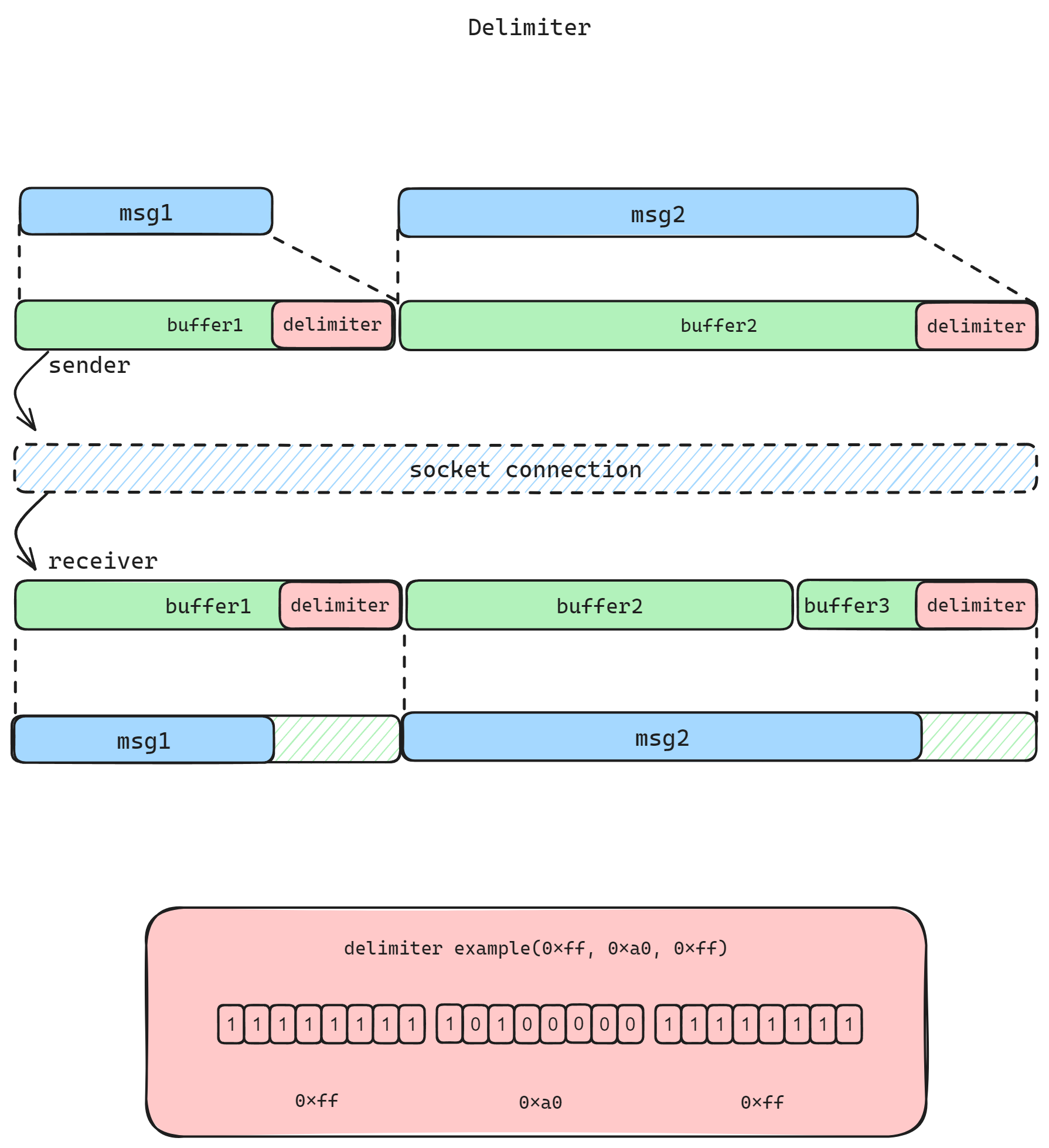
代码样例:
const delimiter = [0xff, 0xa0, 0xff];
const delimiterBuffer = Buffer.alloc(delimiter.length);
delimiter.forEach((d, index) => delimiterBuffer.writeUInt8(d, index));
const delimiterLength = delimiterBuffer.length;
function send(message: any) {
const msgBuffer = v8.serialize(message);
// 消息末尾追加分隔符序列
const data = Buffer.concat([msgBuffer, delimiterBuffer]);
client!.write(data);
}
// 待处理的字节
let pendingBuffer: Buffer = Buffer.alloc(0);
function receive(data: Buffer) {
pendingBuffer = Buffer.concat([pendingBuffer, data]);
function parse(packetBuffer: Buffer) {
const msgBuffer = packetBuffer.slice(0, packetBuffer.length - delimiterLength);
console.log('receive msg:', v8.deserialize(msgBuffer));
}
do {
let matched = false;
let count = pendingBuffer.length - delimiterLength;
let i = 0;
// 二重遍历,找到第一个匹配的分隔符序列的位置
for (i = 0; i <= count; i++) {
for (let j = 0; j < delimiterLength; j++) {
const p = pendingBuffer.readUInt8(i + j);
if (p !== delimiter[j]) {
break;
}
if (j === delimiterLength - 1) {
matched = true;
}
if (matched) {
break;
}
}
}
if (matched) {
// 找到了分隔符序列,拆出消息部分解析
const remainingIndex = i + delimiterLength;
const packetBuffer = pendingBuffer.slice(0, remainingIndex);
pendingBuffer = pendingBuffer.slice(remainingIndex);
parse(packetBuffer);
} else {
// 未找到分隔符序列,跳出循环,等待接收更多的 buffer
break;
}
} while (true);
}
在上例中,我们使用了三个 utf8 字符序列 0xff, 0xa0, 0xff 作为消息结束的分隔符序列。解析时,通过二重循环遍历查找待处理的 buffer 中的该分隔符序列,并提取消息内容本身。这种方式对消息的长度没有什么限制,但需要注意分隔符必须要足够特殊,避免实际的消息内容也携带该字符序列导致的错误解析分隔的情况,所以通常会使用 0xff、0xa0 等不常见的非显示字符组合。另外,如果传输数据量较大,二重循环查找分隔符序列可能产生循环效率问题,引发线程阻塞。
消息长度封装法
这可能是处理消息边界的最佳方式。对于每个消息,我们首先计算出消息内容(body)长度,然后再构造一个固定长度的消息头(header)并写入消息内容长度。接收者收到消息时,先读取该固定长度的消息头,找到接下来需要读取的消息体内容长度,并截取处理。
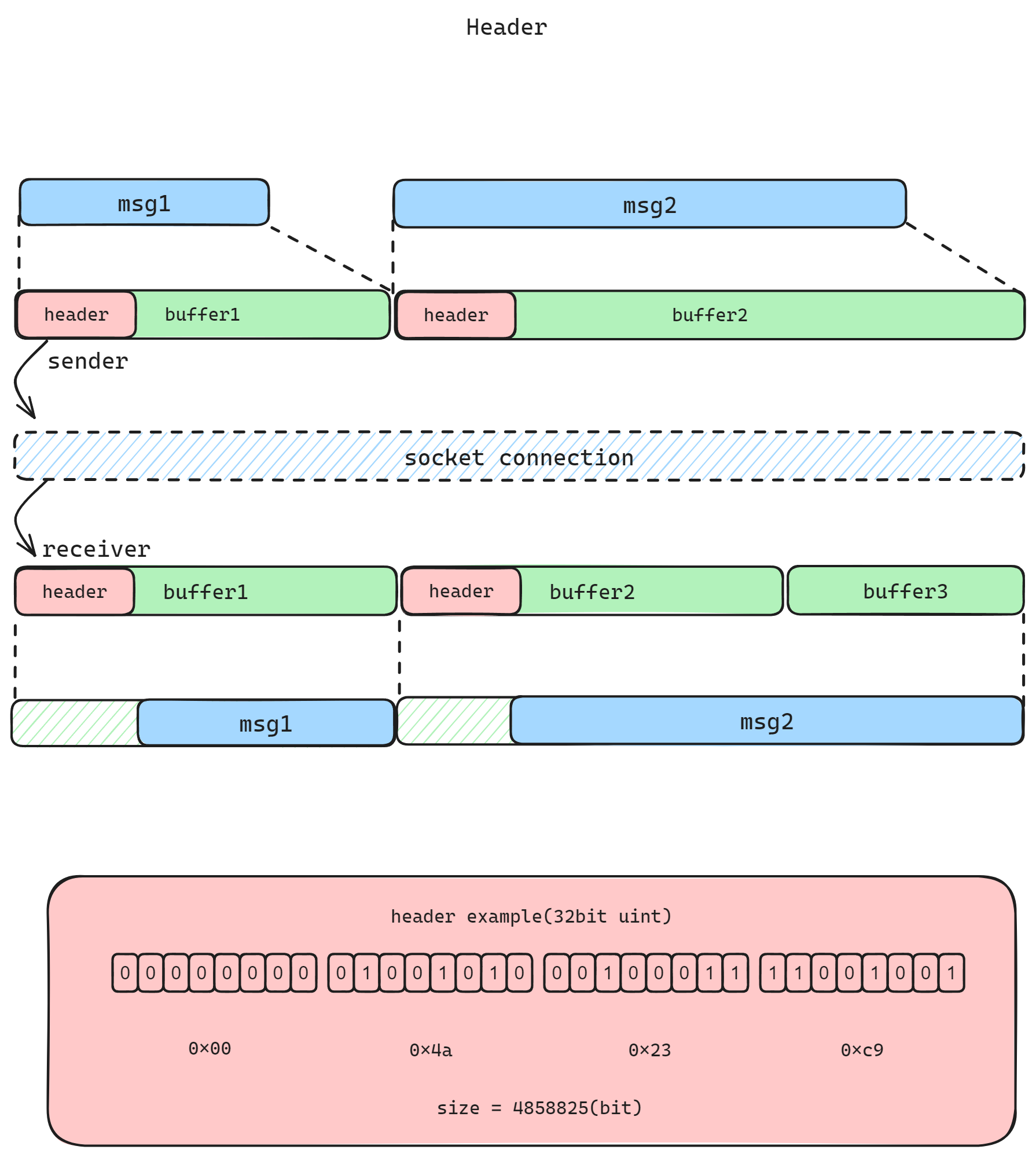
代码样例:
// 消息头位数。用 32 位二进制数(即 4 个 uint8)作为消息长度 */
const DATA_HEADER_SIZE = 4;
function send(message: any) {
const body = v8.serialize(message);
// 构造消息头
const header = Buffer.alloc(DATA_HEADER_SIZE);
header.writeUInt32LE(body.length);
// 组装消息封装
const data = Buffer.concat([header, body]);
client!.write(data);
}
let pendingBuffer: Buffer = Buffer.alloc(0);
function receive(data: Buffer) {
pendingBuffer = Buffer.concat([pendingBuffer, data]);
function parse(packetBuffer: Buffer) {
const msgBuffer = packetBuffer.slice(DATA_HEADER_SIZE);
console.log('receive msg:', v8.deserialize(msgBuffer));
}
do {
// 还不足以解析为一个消息头,跳出并等待更多数据
if (pendingBuffer.length < DATA_HEADER_SIZE) {
break;
}
const bodyLength = pendingBuffer.readUInt32LE(0);
const packetLength = DATA_HEADER_SIZE + bodyLength;
// 还不足以解析为一个消息头加上其表征的完整数据内容,跳出并等待更多数据
if (pendingBuffer.length < packetLength) {
break;
}
// 截取消息封装
const packetBuffer = pendingBuffer.slice(0, packetLength);
pendingBuffer = pendingBuffer.slice(packetLength);
parse(packetBuffer);
} while (true);
}
与前两种办法相比较,得益于 node.js 中 buffer 对象自带的 readUInt32 以及 writeUInt32 方法提供的便利,整个实现过程显得较为简单,基本没有多余的循环、嵌套等逻辑,但却能很高效的处理几乎任何长度消息的构造、解析。需要注意的是,要发送的消息内容长度不能超过消息头能表征的最大数字。在上例中,我们使用 4 个 unit8 即 32 位二进制数作为消息头,可支持的内容长度为 2^32 = 4Gb,实际使用中几乎已是不可能达到的上限了。
总结
充分理解消息边界问题,并通过以上三种方法,我们将能够安全、高效的处理进程间通信的消息边界问题。当拓展到其他需要进行 socket 通信的场景或其他编程语言时,也可以通过类似的方式进行消息的封装、解析。
以上的示例代码均没有考虑多轮循环可能产生的冗余遍历、异常解析数据的处理、node.js 构造 buffer 的开销等问题。实际生产的代码中,这些都需要额外的关注、考虑,并给予合适的优化,限于篇幅,本文中对此不再赘述。