- Git 是怎样管理版本的,切分支为什么这么快?
git log或文件的Git history是按照变更操作的时间顺序线性排序的吗?- 代码是如何合并的?合并时为什么有时会产生冲突?
merge和rebase有什么区别,应该怎样使用?Fork和Pull Request是如何实现的?
在协同开发中,不可避免的需要使用 Git。也许你已经对一些常规命令例如 pull add push commit 有相当熟练的理解和使用了,但这些可能只是 Git 强大功能的一小部分。本文将会结合自己在工作中遇到的一些实际问题,尝试从原理上理解相关概念,探讨 Git 在版本控制、代码管理、多人协作等方面的最佳实践。
版本管理策略
在没有使用版本控制软件之前,为了保存某个文件在某一时刻的状态,我们通常会把它直接复制一份——也许还会给它加上时间戳重命名,例如 file.20180329.js。这种方式足够简单有效。但是当文件版本很多、或者需要保存的文件很多时,这种做法就显得繁琐而低效了。
如果在每次需要保存版本的时候,通过对文件前一个存储状态的差异比较,仅存储这次变更(Deltas)的部分为补丁集,那么就可以极大的减少每个版本的存储数据量。并且,通过对文件应用变更补丁集,能够计算取得文件在任意版本的内容。Subversion 是采用这种策略的代表之一。虽然存储空间上友好了,但可以推测,如果想获取某个文件在某个版本状态下的内容,就必须沿着版本历史遍历计算才能拿到最终需要的结果——如果历史线非常长,这个操作就有可能比较耗时。
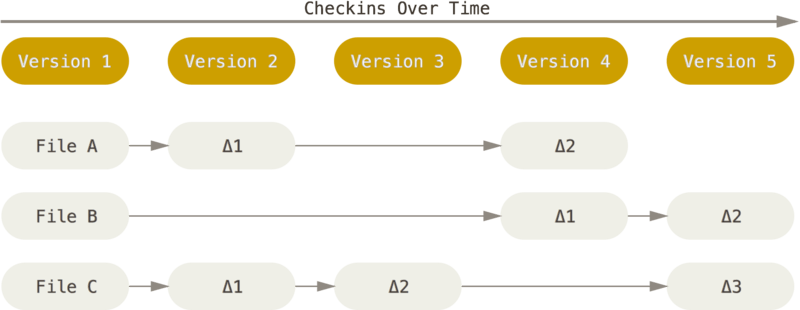
不同于上面的两种方式,Git 采用了对文件做快照(Snapshots)的方式储存版本。对于变更中没有变更的文件,快照不变;有变更的文件,会生成额外的快照存储在本地。因此,Git 在本地存储了版本时间线上的各个版本的全部文件快照。当你在各个版本之间切换时,对于 Git 来说,只是在本地文件快照里找到目标版本文件并呈现给用户,因此非常的快,几乎不需要额外计算。可能你会担心存储如此多的文件快照会占用大量的存储空间,但 Git 在存储空间上做了去重、压缩等优化方案;在传输时也会应用变更压缩的方式,从时间和空间上提高效率。更具体的,可以参考 git-scm book。
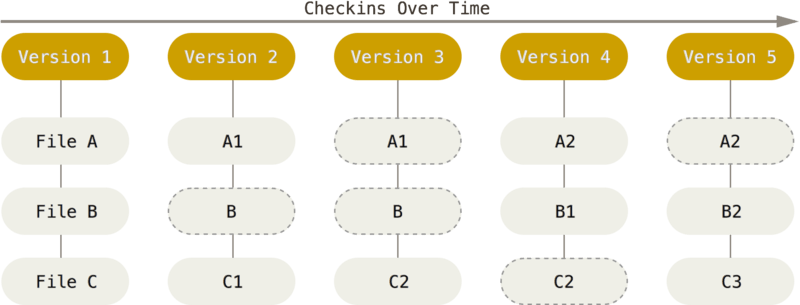
另外,Git 的这种完备快照而非最新快照的特点,也让它拥有了另外一个特点:分布式版本控制(Distributed Version Control)。每个客户端都具备完整的代码仓库,因此在必要的时候,任意一个克隆的客户端都能充当代码的主仓库。
概念和操作
我们先从一些熟悉的 Git 操作入手加深理解。可能很多人初次接触 Git 都是从 github 上新建仓库开始:
一个典型的 Git 工作流程大致如下:
git init: 初始化 Git 仓库;git add: 添加需要追踪变更的文件;git commit: 保存本地变更;git remote add: 设定本地仓库对应的远程仓库地址;git push: 推送本地变更到远程;git pull: 其他人从远端获取变更并同步到本地。
在工作目录的文件,无论如何修改,它总是处于以下几种状态之一:
- 未被加入版本追踪。通常这些是不需要管理版本的文件,使用
.gitignore来匹配控制; - 已加入版本追踪,已提交(committed)。已提交表示数据已经安全的保存在本地数据库(
.git文件夹)中; - 已加入版本追踪,已修改(modified)。已修改表示修改了文件,但还没保存到数据库中;
- 已加入版本追踪,已暂存(staged)。已暂存表示对一个已修改文件的当前版本做了标记,使之包含在下次提交的快照中。
因此,Git 对文件的操作也因此可以划分为 工作区(Working Area)、暂存区(Staging Area) 以及 提交区(Commit Area) 这三个区域。通过一系列命令,Git 操作文件在这几个区域内进行流转。
以下是一些常用 Git 操作的浅析和理解。
Add
将一个或多个文件的临时变更加入暂存区。此时这些变更只在你本地,并且对于 git 版本来说是临时的、未保存的。
常用操作:
git addgit add -A
Commit
Commit 这个单词也出现在 SQL 的事物操作里,意即把一系列数据的变更保存写入。和数据库里的概念类似的,git commit 意即将一个或多个文件的临时变更存储起来,保存到提交区。
一次 commit 包含了以下信息:
- 变更发生前的文件节点 id.
- 文件变更元信息;
- 变更操作者;
- 变更时间戳等。
依据这些信息,Git 会自动生成一个唯一 SHA1 哈希值作为此次变更的 commit-id;同时,Git 也会生成有变更的文件的快照。如果其中某些信息变更了,commit-id 也会发生变化。这样一串连续的变更组成了文件的变更记录——这个数据结构看起来类似单向链表,只不过每一个节点持有的是前一个节点的 id —— 这样也能解释为何 Git 的很多图例里 commit 节点间箭头指向与时间顺序相反。不过,当我们在多个分支演进、合并时,情况会更加复杂,commit 的性质也会更加特殊,我们暂且略过。
常用操作:
git commitgit commit -m 'feat: awesome feature'git commit --amendgit commit --amend -m 'feat(XXXX): awesome feature'
Merge
按照通常的理解,一个分支就是由一串 commit 节点构成的时间线,合并分支则是把多个时间线组合起来的过程。在组合过程中,Git 会寻找这两个时间线的共同的先祖节点,并在此节点的基础上依据各分支的末端节点所指的快照,做一个的三方合并。
假如共同的先祖节点已经是当前分支的末端节点了,那么可以认为目标分支是基于最新的当前分支变更修改而来,此时它们的合并只需要把修改的那些节点转接回当前分支即可。这个过程又叫做 fast-forward 合并。fast-forward 合并不产生新的提交节点。
考虑以下不满足 fast-forward 合并的情况:
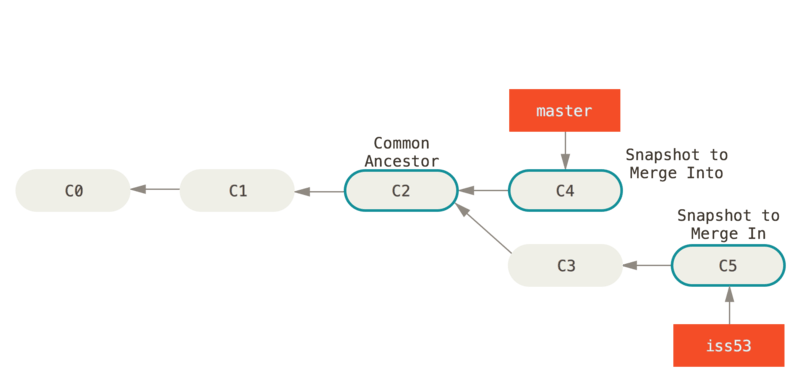
如图所示,这两个分支的合并结果只与共同祖先 C2、master 分支的末端节点 C4、iss53 分支的末端节点 C5 这三方的状态有关;iss53 的中间态 C3(或者 C3.1、C3.2、C3.3等) 做了些什么、是什么时间顺序,完全不影响结果。
这和之前的主观臆断的理解 “merge 操作是按时间顺序线性排列,把两方变更逐一应用在原文件上,并形成一串逐个演进的变更历史直到末端状态” 的认知完全不同!试想,假如 merge 就是按照时间顺序打修改补丁,那么即便两个相邻的补丁都修改了同一行,因为时间顺序的关系,也理应不会产生冲突——无非是先修改成这样,再修改成那样的先后覆盖关系。但是实际中合并过程中,合并冲突却是非常常见的。
这种在 no fast-forward 合并时由 Git 自动生成的合并节点比较特殊,它拥有两个上级节点的引用,标识它是通过哪几条时间线合并而来。因此在主干分支看来,并不是完全糅合时间线了,而只是在某一时刻起殊途同归了。因此,(no fast-forward)合并后的 Git History 并非是线性的。
需要说明的是:通过 git log 看到的 commit 是按照时间顺序线性排列的。因此,基于它的 Gitlab Branch Commits、Gitlab File History 里都只是目标涉及到的 commit 的时间排序,而不是对文件依次应用这些 commit 的变更的顺序。因此一个 commit list 里,并不是前一个 commit 的最终状态加上后一个 commit 的变更就等于后一个 commit 的状态。
结合 git log 的图形模式,也许能帮助我们更好的理解这一点:
$git log --oneline --decorate --graph --all
* 12e0936 docs
| * 241a2e8 (origin/merge-test-aaa, merge-test-aaa) Merge branch 'merge-test-b' into merge-test-a
| |\
| | * 7bd49d8 (merge-test-b) b: remove line
| | * 286eec6 b: add line
| |/
|/|
| * b107d5e (merge-test-a) a: add line
|/
* 8f7ce1f update docs
在明白了这一点后,回过头来看三方合并这个过程,就容易理解为什么会产生冲突了。三方合并的三方:
- 共同的先祖节点 C2;
- 当前分支的末端节点 C4;
- 目标分支的末端节点 C5。
在合并时,相当于往先祖节点 C2 应用 C4 和 C5 各自相对于 C2 的变更。如果这些变更中涉及到同一处代码,Git 就无法自动判断,因此会留下一个冲突交由开发者手动解决。至于如何解决冲突,请参考 git-scm book,本文不再赘述。
常用操作:
merge --no-ffmerge --ff-only
Rebase
通过前面的 merge 操作,在 no fast-forward 的情况下,Git history 会变得非线性、错综复杂。此时可以使用 rebase 改善这个状况。Rebase(变基)意即变更基础节点。假如某功能相对于主分支增加了若干 commit, rebase 就是把这些 commit 依次转接到主干分支末端的操作——这听起来很像一个 cherry-pick 序列。在处理完之后,只需要简单的进行一次 fast-forward 合并即可把功能线性接在主干分支上,因此 Git history 非常清晰。
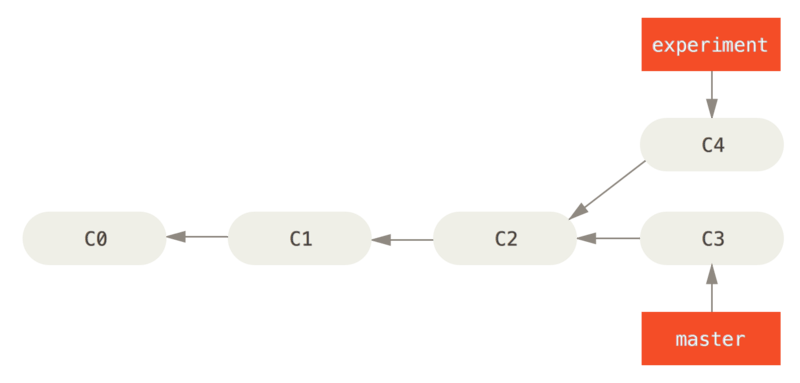
既然 rebase/cherry-pick 是把 commit 逐个应用在目标分支末尾,按理来说就好像自己手动修改了代码保存一样,那么为什么还是会产生冲突呢?这和 rebase/cherry-pick 操作的基节点的选取有关。具体实现原理请参考文末的相关链接。
Rebase 会改写当前分支的 Git history。 由于当前分支的部分 commit 的父节点变更了,这些 commit 实际已经变成了另外一个 commit。假如在 rebase 前这些 commit 已经被合并到主分支并且其他人已在使用,那么在 rebase 后,因为产生了同样功能的新的 commit,其他的副本将不得不和这部分重复的节点做整合,分支就会一团糟。
使用 Rebase 必须谨记以下几点:
- 不要在分支或节点被其他人使用了的情况下 rebase;
- Rebase 相比于 merge 的结果并无二致,区别只在于 rebase 把解决冲突的过程提前了、颗粒化了;
- Rebase 不会让功能合并更简单,反而可能会导致冲突解决的过程更加复杂;
- Rebase 最大的作用是人为的、精心编辑的 Git history。
因此,什么情况下要使用 rebase 可能就比较清晰了:
- 本地开发分支,还未推送到远端(或推送到了远端但没被其他人合并);
- 功能开发完毕,需要本地解决冲突;
- 不美化 Git history 不舒服的强迫症患者。
常用操作:
rebase -i
Remote
回想一下,当我们在 gitlab 上新开一个仓库时,页面上会显示默认的操作提示:
$ cd existing_folder
$ git init
$ git remote add origin <url>
$ git add .
$ git commit -m "Initial commit"
$ git push -u origin master
其中 git remote add origin <url> 意即给本地 git 工作区添加一个名为 origin 的远端仓库,它的地址位于 <url>。平常的拉取、推送代码,都通过这个名为 origin 的远端仓库来进行中转。名称 origin 是在进行这些操作的时候 git 客户端默认去操作的目标。
可以通过 git remote -v 查看当前工作区的远端设置:
$ git remote -v
origin https://git.example.com/merlin/project.git (fetch)
origin https://git.example.com/merlin/project.git (push)
添加多个远程仓库
远程仓库可以添加多个。之前我们用 remote add 为本地的新仓库手动指定了一个远程仓库地址,之后仍然可以用这个命令添加其他名称、其他地址的远程仓库,让本地仓库拥有和多个远程仓库交互的能力:
$ git remote add backup https://git.example.com/edward/project-backup.git
$ git remote -v
origin https://git.example.com/merlin/project.git (fetch)
origin https://git.example.com/merlin/project.git (push)
backup https://git.example.com/edward/project-backup.git (fetch)
backup https://git.example.com/edward/project-backup.git (push)
随后,为了能使用新加的远程仓库 backup 的数据,我们需要先 git fetch backup 拉取该仓库的数据到本地;随后即可基于该远程仓库做分支检出、代码合并、推送等操作。
多远程代码推送
某项目代码在多个 gitlab 仓库上托管,开发者希望某功能本地开发后,能便利的推送到所有的或者指定的远程仓库。可以通过添加多个远程仓库并在推送时指定远程的方式,将代码推送到目标远程仓库上:
$ git remote add mygitlab my-gitlab.com/example.git
$ git push
$ git push mygitlab/master
多远程代码合并
某个在 github 上开源的项目,现需要在公司内部私有改造使用。首先我们 git clone 源代码,并自行改造,将改造后的代码托管在公司私有的 gitlab 上。但是时间久了之后,原开源项目代码仓库里又增加了许多迫切需求的功能。这时,希望能有一种方式把这些新功能整合到我们私有改造的仓库里。此时,给本地仓库添加额外远程仓库,可以便利的达成目标:
$ git remote add github git.github.com/org/example.git
$ git fetch github
$ git merge github/master
另外,远端的地址甚至可以是本地的某个文件目录。当我们需要在多个本地仓库内同步某些改动时,也可以类似的实现。
Fork & Pull Request
前面提到过,Git 是分布式版本控制系统,这使得它为多远程仓库间共享代码提供了可能。上面我们利用手动添加额外远程仓库的方式实现了一些漂亮的操作,在不同仓库之间传输了代码。
如果你经常使用 GitHub,你可能曾经给一些开源仓库提交过 Pull Request。让我们回忆一下这个给开源仓库贡献代码的流程:
- 首先,你并不是这个开源仓库的合作者(collaborators)。为了能提交到该仓库,首先 fork 该仓库,克隆一份到自己名下;
- 在自己的仓库下,切分支实现功能;
- 前往该仓库发起 Pull Request,请求将位于自己仓库的功能分支合并到源仓库的主干分支;
- 源仓库维护者审核了你的变更,并把你的仓库的代码合并到了源仓库,完成 PR。
其中最后的步骤,维护者怎样才能从你的仓库里取走代码到源仓库呢?虽然在网站界面上只是轻轻的一个点击 merge 按钮,但它背后却利用了“多远程代码合并”:先将你的仓库添加为远程仓库,再将你的仓库内的代码合并到本地。这样,即便你不是源仓库的合作者,依然为源仓库贡献了代码。这便是 GitHub 和 GitLab 等集线器式(hub-based)工具最常用的工作流程(参考)。
操作实践
以下是实际工作中遇到的问题以及使用 Git 命令去解决问题的操作实践。
临时存储变更
需求:在开发某功能到一半时,需要立即去处理其他分支上优先级更高的内容,因此需要临时存储当前的开发进度,将工作目录转移到别的分支处理问题,再切回来继续开发。
操作:
stash&stash popcommit&commit amend
在不同分支间转移变更
需求:切到 master 查看某问题,结果忘记 checkout 新分支,直接在当前的本地 master 分支上修改并 commit 了,因此需要把这次修改的变更转移到新分支上。
操作:
reset HEAD^&checkout&add&commitcheckout&cherry-pick <sha>
合并多个提交为一个提交
需求:某功能开发过程中反复修改保存,分支上的提交节点有很多不需要的中间态,因此需要把这些中间态都去掉,合并这些 commit 为一个单独的 feature commit。
操作:
rebase -ilog&reset <sha>&add&commit
多仓库修改代码
需求:在前端两个仓库 project / project-backup 添加基本相同相同的 sentry 监控代码。
操作:
remote add&fetch&cherry-pick
Reference
- https://git-scm.com/book/zh/v2
- https://nvie.com/posts/a-successful-git-branching-model/
- https://github.com/servo/servo/wiki/Beginner%27s-guide-to-rebasing-and-squashing
- https://itnext.io/become-a-git-pro-in-just-one-blog-a-thorough-guide-to-git-architecture-and-command-line-interface-93fbe9bdb395
- https://git-scm.com/book/zh/v2/Git-%E5%88%86%E6%94%AF-%E5%8F%98%E5%9F%BA
- https://stackoverflow.com/questions/49366387/why-extra-changes-in-git-cherry-pick-conflict
- https://stackoverflow.com/questions/10058068/in-a-git-cherry-pick-or-rebase-merge-conflict-how-are-base-aka-the-ancestor/10058070